
代理人。 爬行。 提炼
刮板API
Scraper API 处理解析器、代理、浏览器并自动为您抓取网络。
Scraper API 专为开发人员构建,由 AI 数据提取和防阻塞系统提供支持。 联系我们 如果您需要更多信息。




无限带宽
不用担心抓取大量页面,带宽由我们承担。

停止修理刮板
我们的人工智能为您修复刮板,让您的业务永不停歇。

易于使用的 Scraper API
由开发人员制作的 API。 不到 5 分钟即可快速启动。


99%
成功率
100%
网络正常运行时间
24/7
专家团队的支持


简而言之 Scraper API
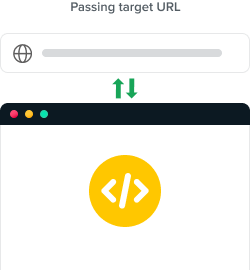


运行流程

1
登录您的 Crawlbase 帐户以获取 API 用户令牌

2
使用用户令牌和完全编码的目标 URL 向 API 端点发送 GET 请求。 使用 cURL 的示例:curl “https://api.crawlbase.com/scraper?token=USER_TOKEN&url=https%3A%2F%2Fwww.amazon.com”

3
等待 API 响应并保存抓取的内容。
数据刮板
可用的刮板
为您的网页抓取或抓取项目找到现成的抓取工具。
Instagram 刮刀
从 Instagram 帖子中获取帖子和个人资料详细信息,包括媒体、主题标签、标题、位置及其相应回复。
从主题标签页面中提取帖子详细信息。
爬网。
建立在 Crawlbase 基础设施之上
Crawlbase 在全球拥有超过 17 个数据中心,可处理来自全球各地和许多不同网站的数据抓取
我们拥有最大的代理网络之一,它将承担您项目的所有负载。
了解如何 Crawlbase 处理抓取。

选择你的计划
选择更适合您需求的刮痧包
免费测试
前 1000 个请求免费。 无需卡。
简单的定价
适用于无隐藏费用的中小型项目。
没有长期合同
Scraper 订阅可以随时取消。
如果您需要更多请求,请 点击这里联系我们!
OR



开始抓取网站并获取数据
免费尝试。 无需信用卡。 即时设置。